This project post does not show how to create a RAG chatbot but see some key considerations for building a production RAG chatbot.
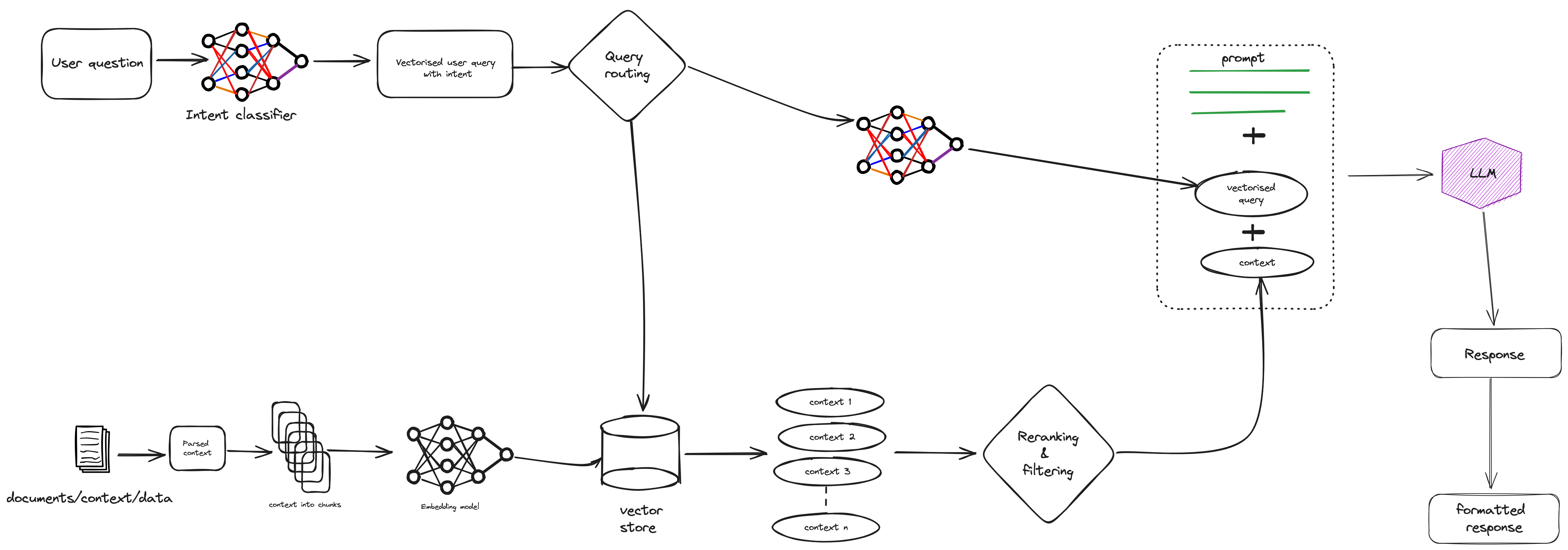
High-level overview of a not-vanilla RAG pipeline
Building a Retrieval-Augmented chatbot can be done easily using OSS stacks, LangChain or LlamaIndex with vector databases such as FAISS and pretty UIs (Gradio or Streamlit) with API calls to OpenAI or using local LLMs with llama-cpp-python.
This post will not be on how to create a vanilla RAG chatbot but take a brief look at some interesting points to make a RAG for production. A high level overview of that pipeline can be seen in the image above.
0. Customised Chunking and Retrieval Strategies
This is the most important part to consider when constructing the RAG pipeline.
Tailoring chunking and retrieval strategies to specific data types and user needs can improve the effectiveness of a RAG chatbot. Using the chunking technique is important especially if there’s a large volume of data. This allows breaking down the data into smaller chunks in order to feed to the LLM relevant chunks of context instead of one whole document.
Retrieval methods are important to consider for contextually richer responses. One basic retrieval method is the search index where content is stored in a vector form. Typically, cosine similarity is used between the query and content vectors. A more advanced method is using vector indexes like faiss. In scenarios where you have multiple documents, the hierarchical index retrieval can be used - that is, using two indices where one index is for summaries and the other for document chunks.
Once the information is retrieved, we can also apply reranking and filtering which is basically refining the retrieved context. Reranking is typically a reranker model that ranks retrieved top-k contexts in a new order to get the most relevant contexts at the top. LlamaIndex has postprocessors and LangChain has flashrank reranker that can be quickly tested in notebooks.
1. Intent Detection and Query Routes
Intent detection serves as the backbone of user interaction within a RAG chatbot. By accurately identifying and classifying user intents, a chatbot can direct queries along specific routes, optimising the use of context while enhancing the accuracy of responses. This can involve special prompt engineering, keyword extraction and special inference to align closely with the intended outcomes, and possibly specific chain-of-thought. The reason to want this is to correctly understand a user’s question and extract the intent and possibly use a specific prompt template. If the user starts a conversation with greetings or asking irrelevant question, another prompt or query route can be used. A query route is typically the next step in a RAG pipeline given a user’s question, and can used to select the appropriate datastore. LlamaIndex and LangChain have more information on these.
2. Testing for Accuracy and Relevance
To ensure reliability and accuracy, the RAG chatbot should be tested against a ground truth set of questions. Techniques such as cosine similarity and semantic similarity can be employed to evaluate the responses’ accuracy, completeness, and relevance. One can go further by examining the relationships between answer-query and answer-context. This additional testing can give insights on how the chatbot performs across multiple queries.
3. Response Formatting
While LLMs can return retrieved data or answers, it is important to present them in readable format or user-friendly tables and lists. One route I’ve been using recently is converting the retrieved information into markdown (markdown tables look good).
4. Citing Sources
Just getting the retrieved data into a formatted answer is not enough. Although this can be hidden from the user’s conversation window, the LLM can be ‘prompted’ to cite the parts of the source documents referenced in its response. Or if this cannot be done, one simple method is to take the generated answer, embed it and compare that embedding to the embedded data in chunks and finally compare their similarity to get the most relevant cited source.
5. Asynchronous API Calls: Enhancing Responsiveness
The integration of asynchronous API calls, for example to OpenAI, enhances the chatbot’s ability to handle multiple requests efficiently. To be fair, I haven’t really tried out async calls to OpenAI and alternatives but here is a doc I’ve looked at.
6. Modularised Infrastructure
LangChain and LlamaIndex are great but I’d personally avoid building the whole infrastructure using same framework. For example, conversation history, context and chunking should be handled separately in a modularised container sort of way.
7. Utilising a Database for User Interactions
Maintaining a database for user sessions, chat history, and other interactions enriches the user experience by personalising responses and understanding long-term user behaviour. This is invaluable in the long term for continuous improvement of the chatbot.
8. Vectored Database Integration
The use of a vectored database enhances the retrieval process by efficiently storing and querying vector representations of data, which is crucial for matching queries with the most relevant information snippets in real-time. Typical vector dbs are faiss, chroma or pgvector with postgreSQL.
End
This is not an exhaustive list of items and can be updated further with “new” developments such as Skeleton-of-Thought and its LangChain template. I hope this post helps you in building a RAG pipeline, and if you focus on some of the listed items, from intent detection to custom retrieval method, the RAG pipeline can give better results.
References/Links
- https://python.langchain.com/v0.1/docs/use_cases/question_answering/
- https://docs.llamaindex.ai/en/stable/getting_started/concepts/
- https://github.com/facebookresearch/faiss
- https://www.gradio.app/guides/creating-a-chatbot-fast
- https://github.com/streamlit/example-app-langchain-rag
- https://github.com/abetlen/llama-cpp-python
- https://docs.llamaindex.ai/en/stable/module_guides/querying/router/
- https://python.langchain.com/v0.1/docs/expression_language/how_to/routing/
- https://python.langchain.com/v0.1/docs/use_cases/question_answering/citations/
- https://docs.llamaindex.ai/en/stable/examples/pipeline/query_pipeline_async
- https://blog.gopenai.com/rag-with-pg-vector-with-sql-alchemy-d08d96bfa293
- https://antematter.io/blogs/optimizing-rag-advanced-chunking-techniques-study
- https://faiss.ai/index.html
- https://pixion.co/blog/rag-strategies-hierarchical-index-retrieval
- https://www.pinecone.io/learn/series/rag/rerankers/
- https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors
- https://python.langchain.com/v0.1/docs/integrations/retrievers/flashrank-reranker
- https://sites.google.com/view/sot-llm
- https://python.langchain.com/v0.1/docs/templates/skeleton-of-thought/